近日,Flux.1 的横空出世,无疑在 AI 文生图领域掀起了一阵轩然大波。作为由黑森林实验室推出的最新开源图像生成模型,它的发布不仅让业内专家为之惊叹,更在短时间内引发了广泛的关注与讨论。无论是从模型的性能,还是其完全免费且支持本地部署的特性,Flux.1 都展示出了极大的潜力,让人们重新审视AI在图像生成领域的无限可能。

网站 blackforestlabs.ai 是由黑森林实验室创建的,该实验室专注于开发和推进最前沿的生成式 AI 模型,特别是在图像和视频合成领域。该实验室由前 Stability AI 的员工创立,旨在推动创造力、效率和多样性的极限。
他们的主要产品之一是 FLUX.1 模型套件,包括三个版本:FLUX.1 [pro]、FLUX.1 [dev] 和 FLUX.1 [schnell]。这些模型针对不同的使用需求,从高端专业应用到个人或本地开发,提供不同级别的服务。FLUX.1 在文本生成图像方面树立了新的行业标杆,超越了其他流行的模型,如 Midjourney 和 DALL·E,在视觉质量、提示词跟随性和输出多样性等方面表现出色。所有这些模型都是完全开源的,并且可以本地部署,使其对于各种用户来说都非常易于访问。


接下来,就为大家介绍2个可以免费使用最新 Flux AI 模型的方式。
方式1:
Hugging Face网站
网址是:https://huggingface.co/black-forest-labs可以通过直接搜索 black forest labs 找到下面👇的页面
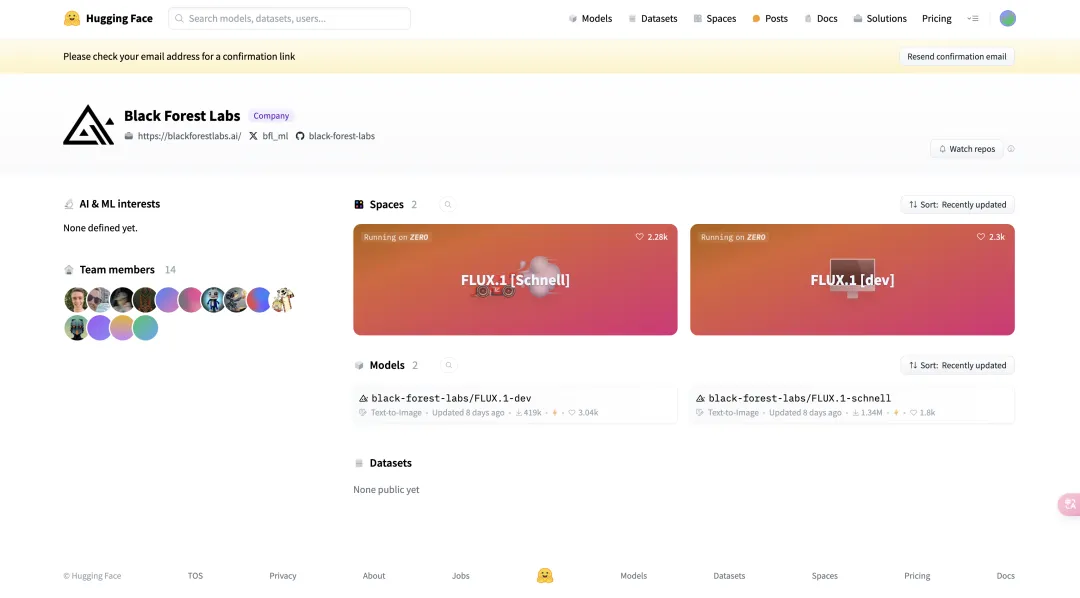
我们可以看到,除了Pro版本,剩下的两个版本——Schnell提速版和dev进阶版,都可以使用。
这里直接使用一下dev进阶版,让我们来感受一下Flux.1 的功力吧~
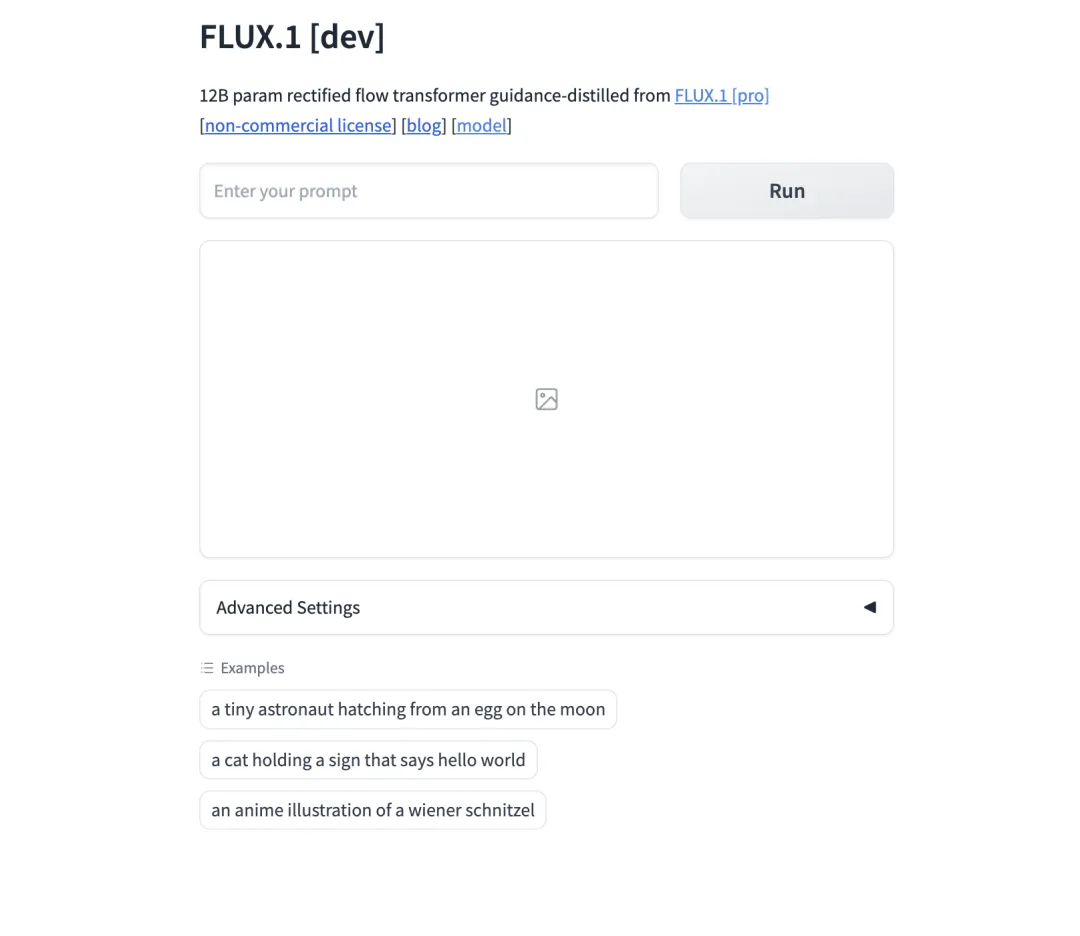
比如我写下—— 一个紫色头发的女孩和一只大型熊猫在街头站立着,熊猫举着一个牌子,牌子上写着“爱生活,爱熊猫”的字样,16:9,赛博朋克风格。
我试图像在perplexit里那样,敲击三次空格键唤醒我的「沉浸式翻译」(前面的文章有介绍过),让它直接转为英文。但是发现唤醒失败。
那么,我们可以让ChatGPT-4o帮忙。
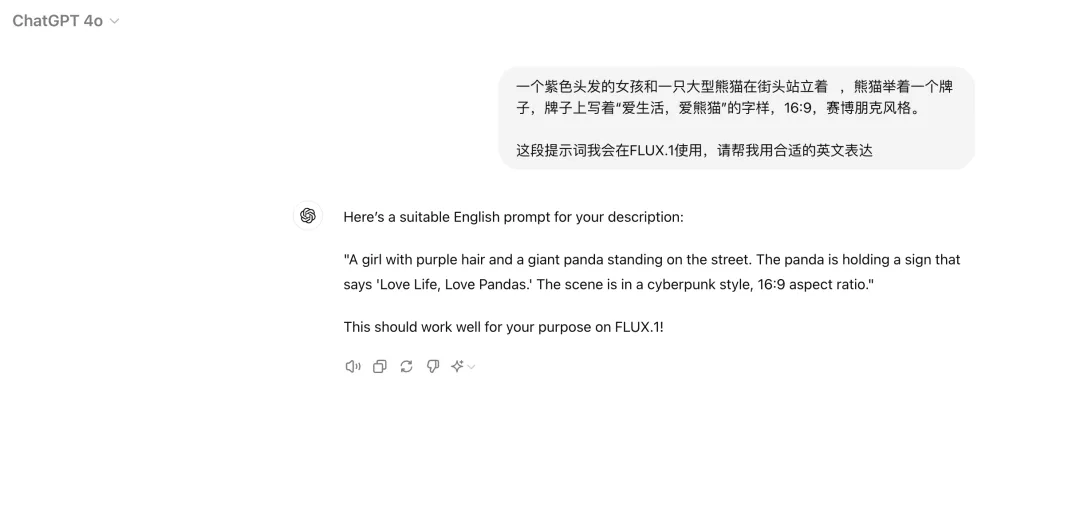
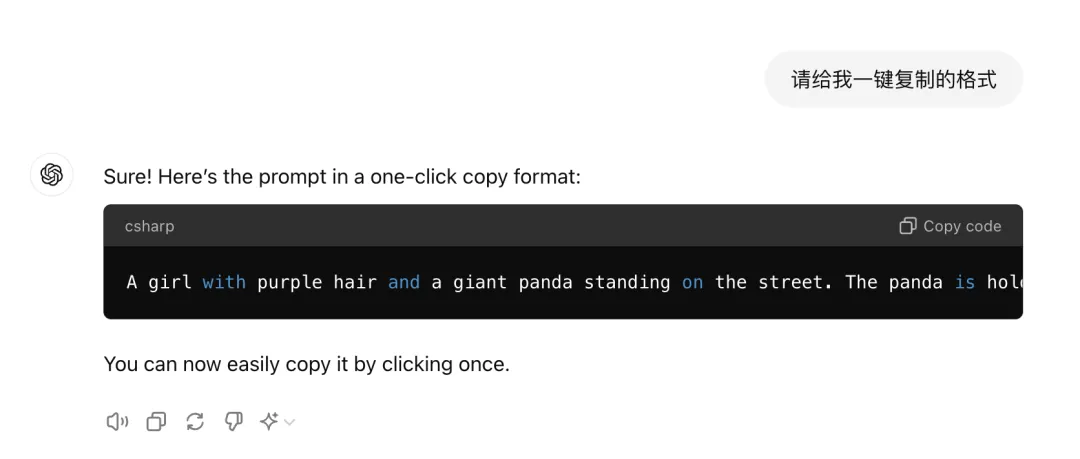
接下去,我们把英文直接一键复制过来。
A girl with purple hair and a giant panda standing on the street. The panda is holding a sign that says ‘Love Life, Love Pandas.’ The scene is in a cyberpunk style, 16:9 aspect ratio.
这里还可以进行高级设置——Advanced Settings:
Advanced Settings(高级设置) 部分允许你微调生成图像的参数。以下是每个设置的含义以及如何使用它们:
- Seed(种子):这个选项控制生成过程中的随机种子。设置一个特定的种子值可以让你生成相同的图片(如果使用相同的提示词和设置)。将其设为0(勾选“Randomize seed(随机化种子)”)则每次都会生成不同的图像。
- 如何使用:如果你希望生成相同的结果,可以取消勾选“Randomize seed”,并手动输入一个数字。否则,保留随机化设置来获得不同的结果。
- Randomize Seed(随机化种子):当勾选此选项时,每次生成时都会使用一个新的随机种子,即使提示词和其他设置保持不变,也会生成不同的图像。
- 如何使用:如果你希望每次生成不同的图像,保持此选项勾选状态。如果你想手动控制种子值,则取消勾选。
- Width(宽度):这个滑块控制生成图像的宽度(以像素为单位)。
- 如何使用:调整宽度以匹配你想要的图像长宽比或尺寸。例如,如果你想要生成一个横向图像,你可以增加宽度。
- Height(高度):这个滑块控制生成图像的高度(以像素为单位)。
- 如何使用:和宽度类似,调整高度以匹配你想要的长宽比或尺寸。例如,对于竖向图像,你可以增加高度。
- Guidance Scale(指导尺度):这个设置决定了生成的图像与提示词的匹配程度。较高的尺度值意味着图像会更接近提示词,但可能会牺牲一些创意。较低的尺度值则允许更多的变化和创意,但可能会偏离提示词。
- 如何使用:可以先从中等值(如3.5)开始,根据你的偏好进行调整。如果你希望图像更符合提示词,增加此值;如果你希望图像更具创意,减少此值。
- Number of Inference Steps(推理步骤数):这个设置控制模型生成图像时的步骤数量。更多的步骤通常意味着更好的图像质量,但也需要更长的处理时间。
- 如何使用:较高的步骤数(如28)可以提高图像质量,但会增加生成时间。如果你在尝试,可以先使用较少的步骤快速生成图像,一旦对提示词满意,可以增加步骤以提升质量。
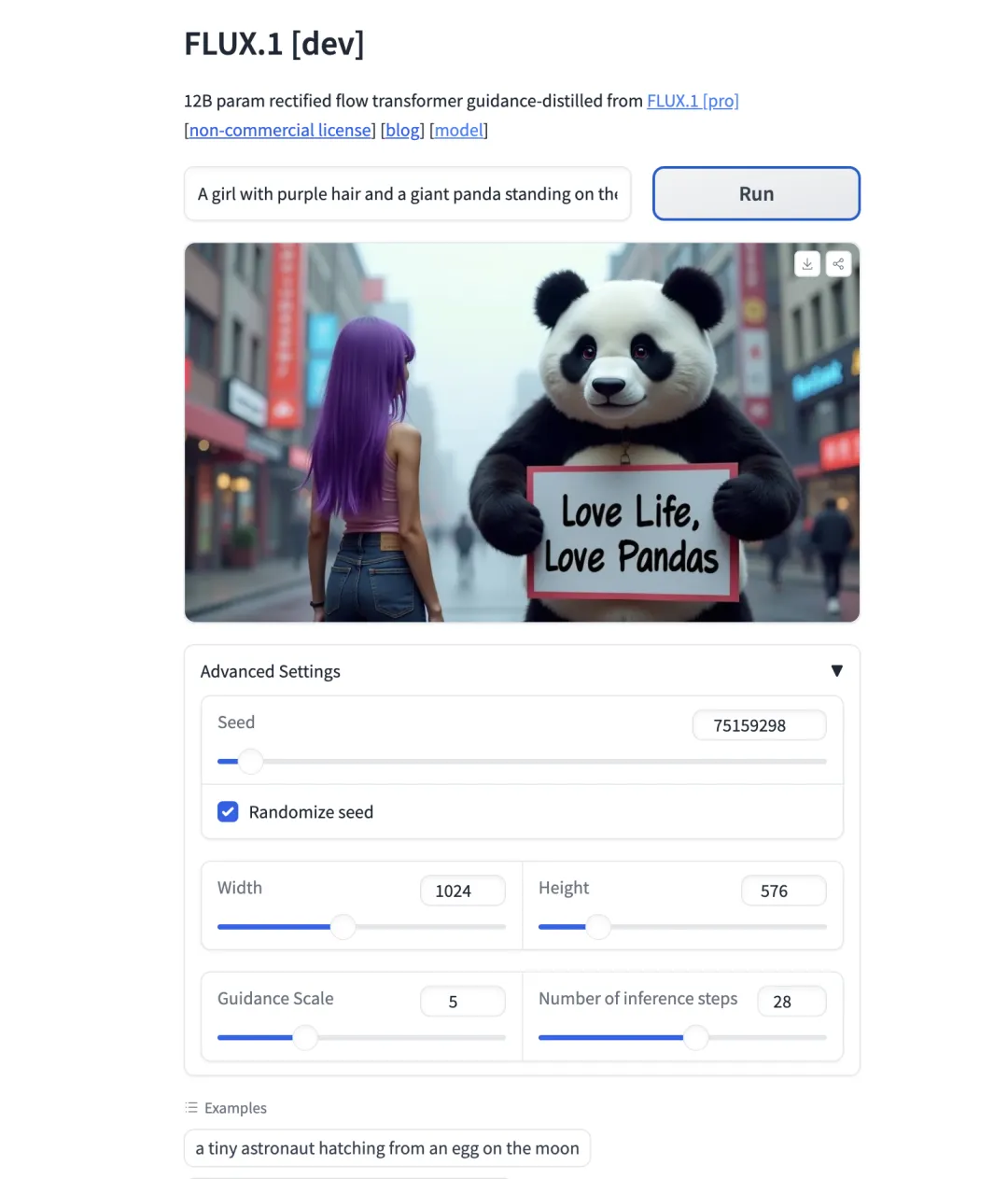
这里我手动调了一下宽高,虽然我的提示词其实是有说需要16:9的尺寸的。然后,我把Guidance Scale增加到了5,因为我希望尽量实现我的提示词需要的内容。
我很满意这个结果!虽然女孩的脸不是正面的,但是这也只需要我去优化我的提示词即可。
对于Midjourney重度使用者的我来说,其实让熊猫举着写有正确字样的牌子这一点就是一个——“概率事件”了。我们可以测试一下:这里再介绍一个小技巧,就是如何生成更适合Midjourney的提示词呢?
如果你正在使用ChatGPT,你可以在Explore GPTs里找到Midjourney的MJ Prompt Generator (V6)。
MJ Prompt Generator”是一个专门为Midjourney这个AI图像生成工具设计的提示词生成器。它的作用是帮助用户创建有效的提示词或指令,使Midjourney能够生成特定风格或内容的图像。在ChatGPT的“Explore GPTs”部分,你可以找到这个生成器,并使用它来优化你在Midjourney中输入的提示词,以便生成你想要的图像效果。
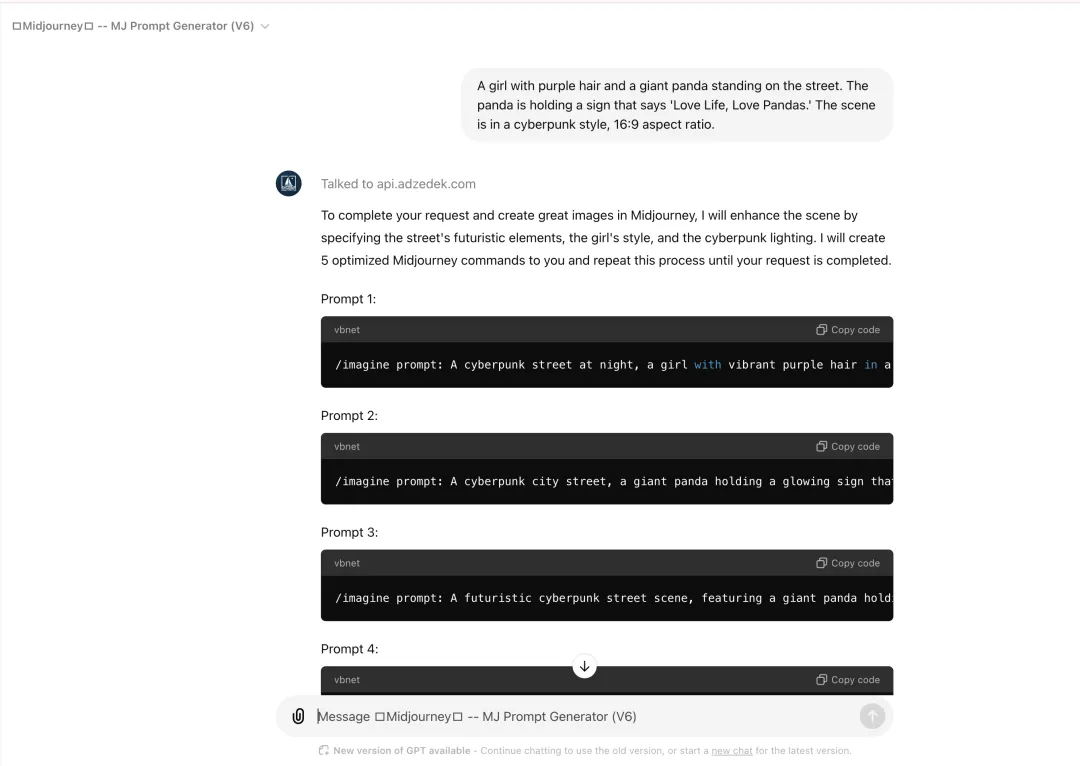
MJ Prompt Generator每次会生成5条,那我们就随机选择第1条——
/imagine prompt: A cyberpunk street at night, a girl with vibrant purple hair in a sleek futuristic outfit, standing next to a giant panda. The panda is holding a neon sign that says “Love Life, Love Pandas.” The street is filled with neon lights, rain-soaked pavement reflecting the city lights, distant skyscrapers towering in the background, holographic billboards. Cool blue and pink neon lighting with dynamic shadows, cinematic atmosphere. Created Using: cyberpunk aesthetic, neon glow, rain-soaked textures, realistic reflections, high contrast lighting, detailed character design, cinematic framing, futuristic cityscape –ar 16:9 –v 6.0
中文翻译:一个赛博朋克风格的夜晚街道场景,一名紫色亮发的女孩穿着光滑的未来派服装,站在一只巨型熊猫旁边。熊猫手中举着一个霓虹灯牌,上面写着“爱生活,爱熊猫”。街道上充满了霓虹灯光,雨水打湿的路面反射着城市的灯光,远处的摩天大楼耸立在背景中,还有全息广告牌。整个场景以冷蓝色和粉色的霓虹灯光照亮,带有动态阴影和电影般的氛围。该图像的美学风格为赛博朋克,包括霓虹光辉、雨水浸湿的纹理、真实的反射、高对比度的光影效果、详细的人物设计和未来主义的城市景观。图像的比例为16:9。
好,基本上是把我的提示词更细致地扩展了。
下面是这段提示词在Midjourney所生成的结果——

只有第二张图,熊猫是举着牌子的。并且我们可以看到,牌子上的字样并不是——”Love Life, Love Pandas”

方式2:
Glif.app平台
在Glif.app平台上我们可以使用Flux的 Pro高级版本。这个平台允许用户构建不同的人工智能应用程序,并提供了多个图像生成模型供选择。通过在提示词中指定摄像机型号和光圈值,我们可以生成具有电影质感的图片。
- 登陆
- 点击Build
- 点击左侧的“+”
- 点击Image Generator
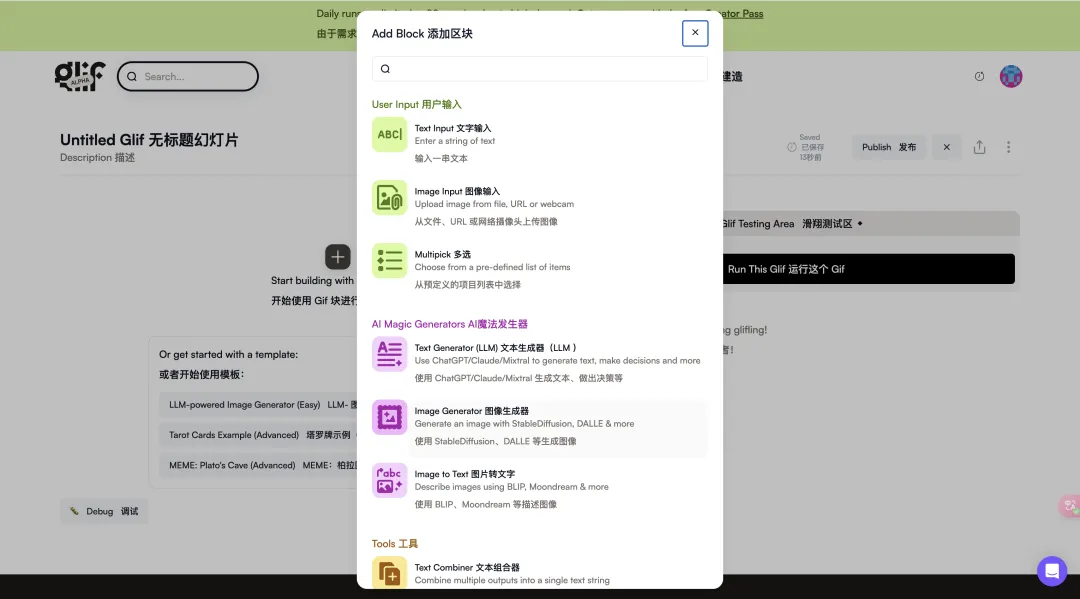
我们可以在这里看到, Flux AI 的三个模式,均可使用。
它的设置也和上面 Hugging Face网站里的类似。
我们用在 Hugging Face网站里的同一段提示词,看看 Flux Pro版本的效果——
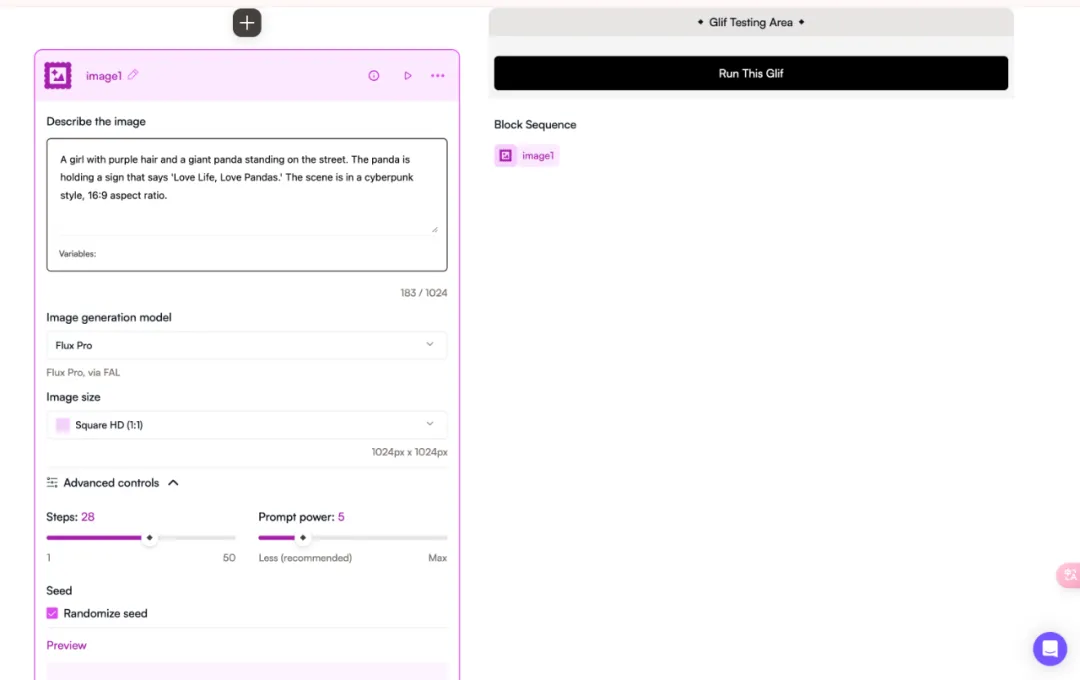

可以感觉到Pro呈现出来的画面的质感确实比dev进阶版是更好的。
那我们再输入前面给Midjourney里更细致的描述词,看一下效果——

经过这次的测试体验,可以感受到Flux AI模型无论是在提示词理解还是图像生成的细节表现上,都非常出色。对于艺术创作者来说,这款开源模型绝对是一个值得尝试的工具。
并且最重要的是,它!现!在!是!免!费!的!